Title here
Summary here
In the previous post (semantics of XPath expressions), the semantics of different XPath notations were discussed. Part 2 will be an in-depth analyses of the SQL queries generated by Mendix for each of the XPath expressions. Furthermore it will shed some light on why these XPath expressions return a different data set. If you haven’t read part 1 yet, please do.
First a quick recap of the data used and discussed in part 1. The goal was to retrieve the teams which have an employee who speaks both Russian and English. However, this example is arbitrary and merely to display the effect of different XPath notations.
| Employee name | Team name | SpeaksEnglish | SpeaksFrench | SpeaksRussian |
|---|---|---|---|---|
| John | Alpha | true | false | true |
| Frank | Alpha | false | true | true |
| Steve | Beta | true | false | false |
| Dan | Beta | true | true | false |
| Mike | Beta | false | true | true |
[Organization.Employee_Team/Organization.Employee/SpeaksEnglish=true()]
[Organization.Employee_Team/Organization.Employee/SpeaksRussian=true()][Organization.Employee_Team/Organization.Employee[SpeaksEnglish=true() and SpeaksRussian=true()]]The following SQL is generated in these scenario’s.
SQL: SELECT "organization$team"."id",
"organization$team"."name"
FROM "organization$team"
WHERE "organization$team"."id" IN (SELECT "a1organization$employee_team"."organization$teamid"
FROM "organization$employee_team" "a1organization$employee_team"
INNER JOIN "organization$employee" ON "organization$employee"."id": "a1organization$employee_team"."organization$employeeid"
INNER JOIN "organization$employee_team" "a2organization$employee_team" ON "a2organization$employee_team"."organization$teamid": "a1organization$employee_team"."organization$teamid"
INNER JOIN "organization$employee" "x2Organization.Employee" ON "x2Organization.Employee"."id": "a2organization$employee_team"."organization$employeeid"
WHERE "organization$employee"."speaksenglish": TRUE AND "x2Organization.Employee"."speaksrussian": TRUE)SQL: SELECT "organization$team"."id",
"organization$team"."name"
FROM "organization$team"
WHERE "organization$team"."id" IN (SELECT "a1organization$employee_team"."organization$teamid"
FROM "organization$employee_team" "a1organization$employee_team"
INNER JOIN "organization$employee" ON "organization$employee"."id": "a1organization$employee_team"."organization$employeeid"
WHERE ("organization$employee"."speaksenglish": TRUE AND "organization$employee"."speaksrussian": TRUE))
The database contains a table “team”, “employee” and a junction table “employee_team”. These are joined via an inner join.
All relations in Mendix are stored in a junction table, even 1-1 relations.
The SQL generated by Mendix for this XPath expression is pretty straight forward. Just to illustrate the built up of the SQL statements we will dissect the query in to smaller sections.
SQL: SELECT "organization$team"."id",
"organization$team"."name"
FROM "organization$team"The first section selects from the “team” table, the id and organization name. The result of this query is the id and name of both teams.
5066549580791809;"Alpha"
5066549580791810;"Beta"This result is constrained via a where-statement on the sub select query. The sub select also contains the constraint.
SQL: (SELECT "a1organization$employee_team"."organization$teamid"
FROM "organization$employee_team" "a1organization$employee_team"
INNER JOIN "organization$employee" ON "organization$employee"."id": "a1organization$employee_team"."organization$employeeid" WHERE ("organization$employee"."speaksenglish": TRUE AND "organization$employee"."speaksrussian": TRUE))The select without the inner join and without where-statement would return all the id’s in the junction table. One for each of the combinations team - employee. In this case:
5066549580791809
5066549580791809
5066549580791810
5066549580791810
5066549580791810After the inner join the data of the junction-table and employee are combined. If the select would not only select the teamid but all fields the joined table would contain these values:

Additionally the sub select is constraint by the where-statement, effectively limiting the selection to the following records of the table above:
4503599627370497;5066549580791809;4503599627370497;"John";t;t;fThese results are combined via the initial where-statement.
SQL: WHERE "organization$team"."id" IN (sub select query)This results in the following data set: 5066549580791809;"Alpha". Only one team is returned, as expected.
The constraint speaksenglish= TRUE AND speaksrussian: TRUE is directly applied to the sub select query and thus limits the selected employees. Furthermore the where-statement is applied on a joined table where the employee section of the table is unaltered.
The SQL query in scenario 4 shows that the sub select is very specific when it comes to constraining the employees. The result of this sub select is then combined with the teams these employees belong to. Thus only once the combination team - employees is made (which is better for performance as noted in part 1).
The SQL generated for the notation with separate XPath constraints is slightly more complicated. The first section of the SQL query is exactly the same as the first section of SQL in scenario 4, I’ll skip that section. The sub query, on the other hand, consists of three inner joins instead of one and the where-statement needs some explanation.
The sub query is depicted below:
SQL: (SELECT "a1organization$employee_team"."organization$teamid"
FROM "organization$employee_team" "a1organization$employee_team"
INNER JOIN "organization$employee" ON "organization$employee"."id": "a1organization$employee_team"."organization$employeeid"
INNER JOIN "organization$employee_team" "a2organization$employee_team" ON "a2organization$employee_team"."organization$teamid": "a1organization$employee_team"."organization$teamid"
INNER JOIN "organization$employee" "x2Organization.Employee" ON "x2Organization.Employee"."id": "a2organization$employee_team"."organization$employeeid"
WHERE "organization$employee"."speaksenglish": TRUE AND "x2Organization.Employee"."speaksrussian": TRUE)and returns
5066549580791809
5066549580791809
5066549580791810
5066549580791810At first sight this might look a little bit off, but it’s correct. The query, however when split into smaller sections does make more sense. The first section of the sub query is also the same as discussed in the paragraphs on section 4 and returns (if you would select * instead of just organization$teamid) the following data:
The second inner join combines the table above with the junction table. The junction table (without any joins or constraints) contains 5 rows; one for each combination team - employee. However this second inner join, joins the junction table result of the select (also the junction table). Creating a joined table with 13 results. This is caused by the way inner joins work, for each match a row records is produced. If we consider the teamid in the junction table:
5066549580791809
5066549580791809
5066549580791810
5066549580791810
5066549580791810A inner join on this table with the same table on teamid would lead to the following situation. The first 5066549580791809 would match the first occurrence in the table, but also the second, and thus creating 2 rows. The second 5066549580791809 would also match the first and second occurrence, generating another 2 rows, in total 4 rows. The first 5066549580791810 would match 3 occurrences, generating 3 rows, the second and third would also generate 3 rows, 9 in total. Thus the inner join depicted below generates 13 rows.
SELECT *
FROM "organization$employee_team" "a1organization$employee_team"
INNER JOIN "organization$employee" ON "organization$employee"."id": "a1organization$employee_team"."organization$employeeid"
INNER JOIN "organization$employee_team" "a2organization$employee_team" ON "a2organization$employee_team"."organization$teamid": "a1organization$employee_team"."organization$teamid"The data set returned by part of the SQL query contains the following records:
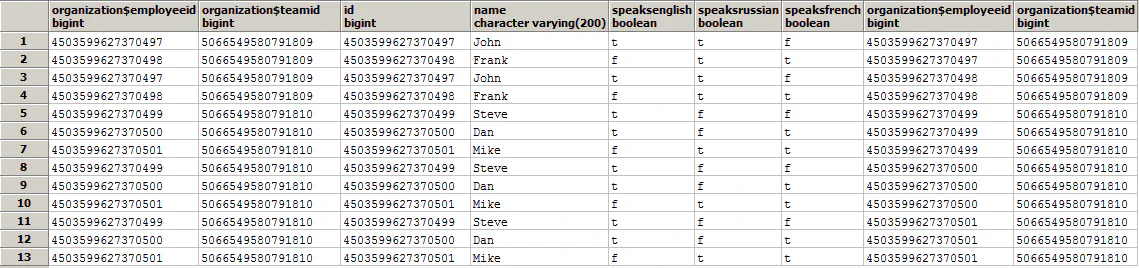
In itself this doesn’t make much sense, but once we add the third inner join (which combines the result above with the employee table) we can see a pattern emerge. The left side consists of the records retrieved by the first XPath constraint and the right side of the table contains the records retrieved by the second XPath constraint.
SELECT *
FROM "organization$employee_team" "a1organization$employee_team"
INNER JOIN "organization$employee" ON "organization$employee"."id": "a1organization$employee_team"."organization$employeeid"
INNER JOIN "organization$employee_team" "a2organization$employee_team" ON "a2organization$employee_team"."organization$teamid": "a1organization$employee_team"."organization$teamid"
INNER JOIN "organization$employee" "x2Organization.Employee" ON "x2Organization.Employee"."id": "a2organization$employee_team"."organization$employeeid"The table below shows the final result of the sub query without the where-statement.

Once we add the where-statement back into the sub query we see that the first XPath constraint is applied to the left side of the table and the second XPath constraint is applied to the right side of the table resulting in the table depicted below. This matches the way we defined the XPath constraints in Mendix: as two constraints in a separate notation.

Finally this table is combined with the first section of the main SQL query (via the initial where-statement) and returns:
5066549580791809;"Alpha"
5066549580791810;"Beta"When considering large data-sets one could see why the queries in scenario 3 are less efficient than the queries generated in scenario 4. The amount of data joined is much larger when using separate XPath constraints using the same associations (because of the repeated join on the junction table). Transfer this scenario to a production environment with a large database and even more XPath constraints on the same retrieve and one has a potential performance killer.
The different notation of XPath constraints effects the way SQL is generated by Mendix to great lengths. And one could see how the retrieve of scenario 4 would out-perform the retrieve of scenario 3. Yet, rewriting the XPath expression is not always better since it may change the semantics of the XPath expression.
In summary, by defining the XPath constraints in a separate notation the actual SQL query will also treat these constraints as such. First the junction table and employee table will be joined for the first XPath constraint, and then the junction table will be joined with the employee table for the second XPath constraint. The result of these two joins are also joined creating a subset on which the where-statement is applied. This may sound fuzzy but is exactly what was defined as XPaths in Mendix.